
Article
深度学习-联邦学习-CH0-FedAvg算法与联邦学习的出现
这份笔记详细记录了联邦学习(Federated Learning, FL)的基本概念、应用场景以及核心算法 FedAvg 的逻辑。
联邦学习 (Federated Learning) 与 FedAvg 算法笔记
Communication-Efficient Learning of Deep Networks from Decentralized Data
1. 场景背景 (Scenario)
目标:政府希望联合六家医院共同训练一个医疗 AI 模型。 核心挑战:
- 隐私问题:医疗数据极其敏感,医院无法直接将原始数据上传给政府或共享给其他机构。
- 带宽问题:原始医疗影像(如 CT)数据量庞大,直接传输会造成巨大的网络带宽压力。
解决方案:采用联邦学习技术,实现“数据不动模型动,数据可用不可见”。
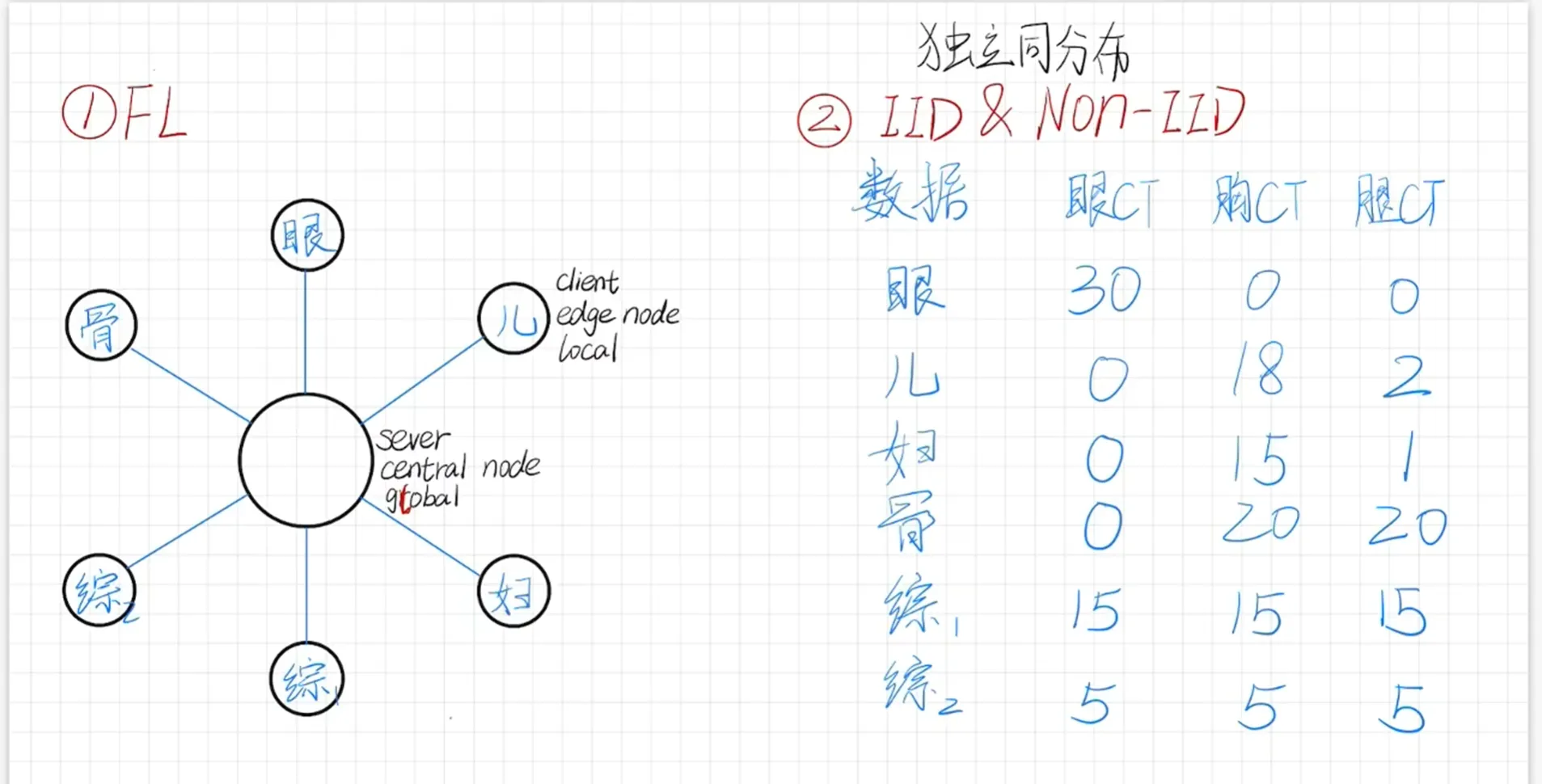
2. 联邦学习架构 (Architecture)
联邦学习通常采用星形拓扑结构:
- 中心服务器 (Central Server / Global Node):由政府/中心机构管理,负责模型的下发与聚合。
- 客户端 (Client / Edge Node / Local):即各家医院,负责利用本地数据进行模型训练。
3. 数据分布问题 (Data Distribution)
在联邦学习中,不同节点之间的数据分布特性对模型效果影响巨大:
3.1 IID 与 Non-IID
- IID (独立同分布):各节点之间的数据分布是相似的。
- 例:多家综合性医院之间的医疗数据分布通常较为接近。
- Non-IID (非独立同分布):各节点之间的数据分布存在显著差异。
- 例:专科医院与综合医院之间,或不同地区的医院之间,数据类别比例不同。
3.2 案例分析:各医院数据分布表
| 医院类型 | 眼部 CT 数 | 胸部 CT 数 | 腿部 CT 数 |
|---|---|---|---|
| 眼科专科医院 | 30 | 0 | 0 |
| 儿科医院 | 0 | 18 | 2 |
| 妇产科医院 | 0 | 15 | 1 |
| 骨科医院 | 0 | 20 | 20 |
| 综合医院 A | 15 | 15 | 15 |
| 综合医院 B | 5 | 5 | 5 |
3.3 思考题
问:既然综合医院的数据分布已经很均衡了,为什么不直接只用综合医院的数据做一个模型?
答:
- 数据总量与泛化能力:联邦学习整合了所有医院的数据,数据样本量更大,模型的泛化能力更强,能更好地应对“长尾分布”或少见病例。
- 数据质量与专业性:专科医院在特定领域(如眼科)拥有更深、更精细的数据。通过联邦学习,可以将专科医院的专业知识迁移到通用模型中,提高模型在特定领域的准确度。
4. FedAvg (Federated Averaging) 算法逻辑
FedAvg 是联邦学习中最经典、最常用的聚合算法。
4.1 基本方法流程
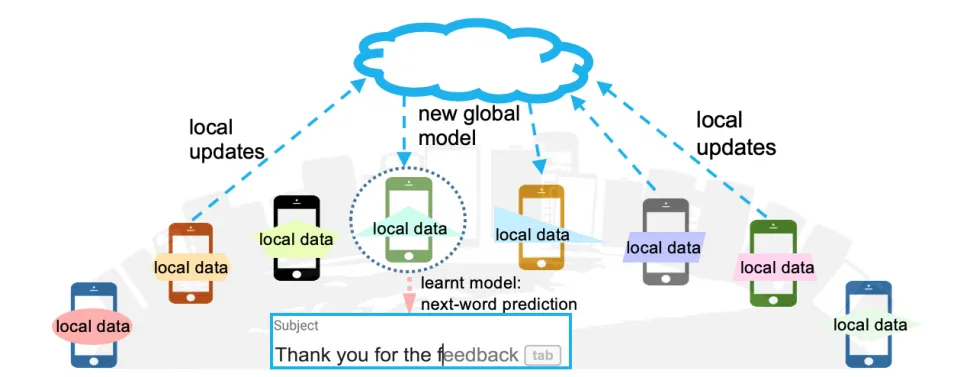
- 初始化:政府(Server)下发一个初始的基础模型参数 。
- 本地训练 (Local Training):各医院(Client)接收模型后,利用本地数据训练模型,得到更新后的本地参数 。
- 上传 (Upload):各医院将更新后的模型参数(或梯度)上传给政府。
- 加权聚合 (Aggregation):政府收集各家模型,按照各家数据量的大小进行“加权平均”,生成新的全局模型。
- 广播 (Broadcast):政府将更新后的全局模型再次分发给各医院。
- 迭代:重复以上步骤,直到中心服务器认可模型效果或达到预设的训练轮数。
4.2 核心算法伪代码

算法参数定义:
- :每轮参与计算的客户端比例。
- :每个客户端在每轮中对其本地数据集执行的训练通过数 (Local Epochs)。
- :客户端更新时使用的本地小批量大小 (Local Batch Size)。
伪代码流程:
- Server 端执行:
- 初始化
- 对于每一轮 执行:
- (随机抽取客户端)
- 对于每一个被选中的客户端 并行执行:
- (根据数据量占比进行加权聚合)
- ClientUpdate() 局部更新:
- 将本地数据 划分为大小为 的多个批次 (Batches)。
- 对于每个本地 Epoch 从 到 执行:
- 对于每个 Batch 执行:
- (执行 SGD 随机梯度下降)
- 对于每个 Batch 执行:
- 将更新后的 返回给 Server。
5. 关键总结
- 权重决定权:在聚合时,每个 Client 对全局模型的贡献权重是由其拥有的数据量占总数据的比例决定的。
- 通信效率:通过增加本地迭代次数 ,可以减少 Client 与 Server 之间的通信频率。
- 本质:FedAvg 本质上是带权重的局部随机梯度下降(Local SGD)的聚合。