
Article
CH4数据通路和流水线
围绕处理器中的数据通路与流水线设计,梳理关键部件协作方式以及性能优化背后的底层逻辑。
概览
我们主要学习了三类指令
-
R型指令 (add,sub,srl等)
-
数据传输指令(LW/SW 等)
-
条件分支指令(beq,bne)
以及跳转指令和其他指令。
我们将会发现,底层的运行逻辑建立在如何执行这些操作。
以及我们需要明白一件事
整个数据通路和流水线,在做的事情就是传递数据信息和控制信息
数据通路
流水线
流水级
我们将流水线分为5个stage
- IF: 取指令。
- ID: 指令译码,读寄存器堆。
- EX: 执行或计算地址。
- MEM: 访问数据存储器。
- WB: 写回。
问题
结构冒险 Structural Hazard
当多个流水级在同一时刻竞争同一个物理资源(如单一的内存端口)时,就会发生Structural Hazard。
数据信息问题-数据冒险
对于R型指令,比如add,我们会发现存在一些问题
add $t0 $s1 $s2
sub $t0 $t0 $s1前一个指令在t2才能得到数据,后者在t3就需要数据。
后一条指令需要读取前一条指令写入的结果也就被称为Data harzard
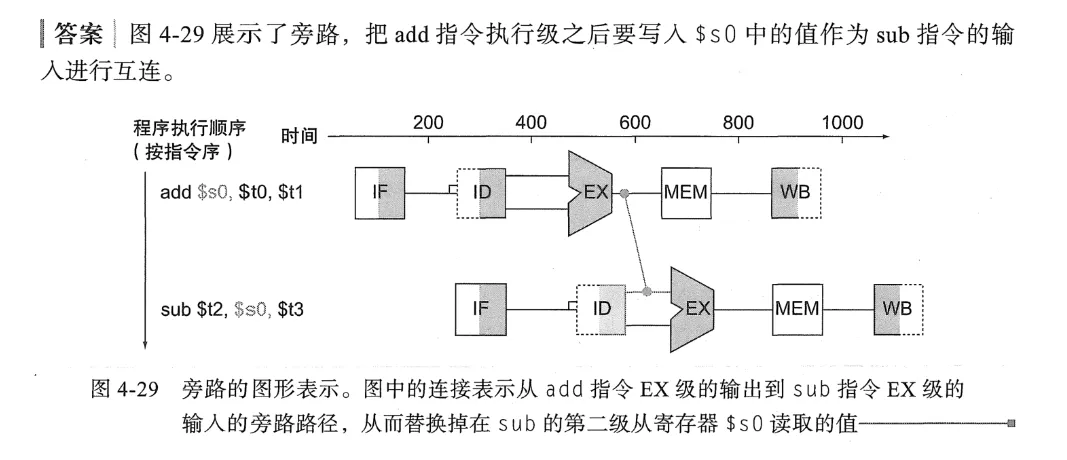
Bypass
通过Bypass实现数据的传播,将原本wb之后才能得到的数据提前传输。
该技术允许数据在未正式写回寄存器堆之前,直接从内部缓冲区或寄存器传递到需要它的单元。
load-use Data harzard
虽然旁路可以解决相邻流水级的数据传输。
但是如果间隔太大呢。
比如 lw 需要在 MEM 获得数据
但是add 需要 EX 使用数据
中间只能通过 nop 阻塞和 bypass来实现
控制信息问题-控制冒险
什么能够影响到控制信息呢?
分支指令。
当我们在执行的时候,我们无法知道后面的指令是否有必要执行,这也就造成了一种不确定性
- 阻塞:通过气泡,得到结果后在执行后面的操作(最为朴素的做法)
- 预测:也就是前面的八大思想之一