
Article
信息论-CH3-信源编码
信息论-CH3-信源编码,待补充摘要。
第三章 信源编码 (Source Coding)
1. 信源编码的基本概念
1.1 编码的目的与目标
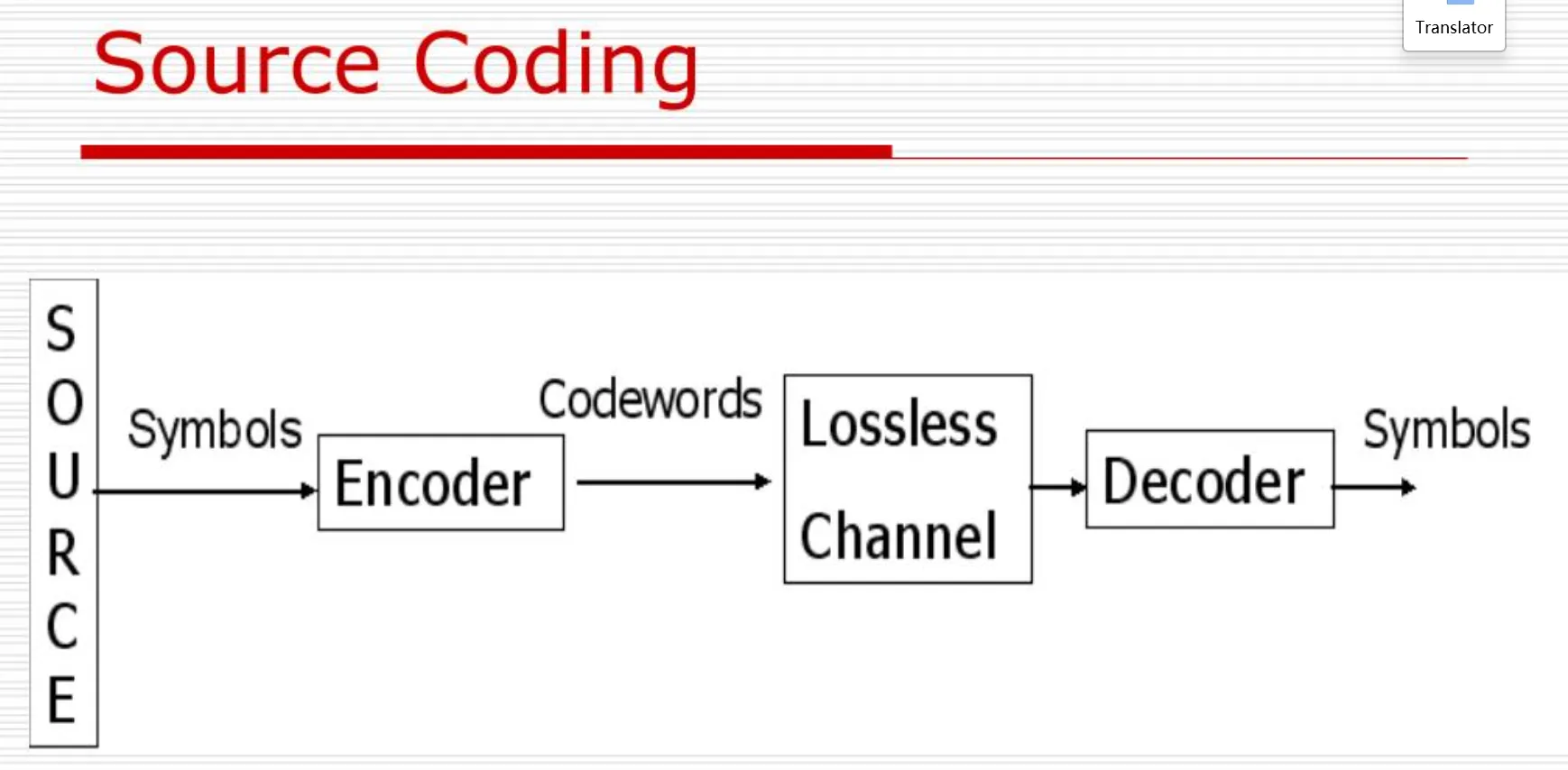
- 主要目的:减少信源剩余度(冗余),提高传输的有效性。
- 信息传输的两个核心指标:
- 有效性(Effectiveness):对应信源编码,旨在压缩数据。
- 可靠性(Reliability):对应信道编码,旨在抗干扰。
1.2 码的分类
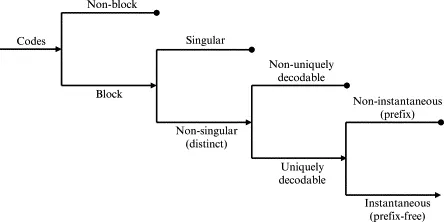
- 分组码(Block Codes):将信源符号序列划分为固定长度的组进行编码。
- 非分组码:
- 奇异码(Singular Codes):存在不同的信源符号对应相同的码字。
- 非奇异码(Non-singular Codes):每一个信源符号对应唯一的码字(不能重复)。
- 唯一可译码(Uniquely Decodable Codes):任意有限长度的码字序列只能被唯一地分割成一个个码字。
- 即时码 / 前缀码(Instantaneous / Prefix Codes):没有任何一个码字是其他码字的前缀。接收端无需参考后续码字即可当场译码。
- 非即时码:虽然唯一可译,但可能需要参考后续符号才能确定当前码字。
- 即时码 / 前缀码(Instantaneous / Prefix Codes):没有任何一个码字是其他码字的前缀。接收端无需参考后续码字即可当场译码。
- 唯一可译码(Uniquely Decodable Codes):任意有限长度的码字序列只能被唯一地分割成一个个码字。
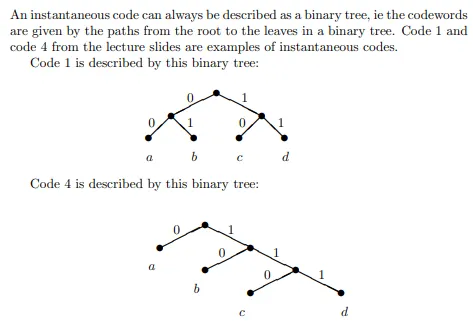
1.3 重要结论
- 定长非奇异码:一定是唯一可译码。
- 即时码判别准则:没有一个码字是其他任意码字的前缀。
2. 唯一可译码的判别 (判定准则)
对于变长码,判断其是否为唯一可译码通常使用后缀搜索法。
2.1 判别步骤 (SOP)
-
找前缀:检查码字集合中,是否存在码字 是另一个码字 的前缀。
-
写后缀:如果存在,将 除去前缀 后的剩余部分(即后缀)提取出来,存入后缀集合。
-
迭代更新:将新产生的后缀加入集合,再次检查:
- 后缀集合与原始码字集合之间是否存在前缀关系。
- 后缀集合内部是否存在前缀关系。
-
持续计算:重复上述过程,直到无法产生新的后缀。
-
判别标准:
- 非唯一可译:如果在过程中,某个后缀本身就是一个原始码字,则该码是非唯一可译码。
- 唯一可译:如果所有支路最终都变为空集(即没有后缀是码字),则该码是唯一可译码。

3. 编码的性能度量指标
所有指标均基于统计平均意义。
3.1 平均码长 (Average Code Length)
平均每个信源符号所需的码元个数:
其中 是信源符号 出现的概率, 是对应的码字长度。
3.2 编码后的信息传输率 ()
平均每个码元所承载的信息量:
3.3 编码效率 ()
实际传输率与最大可能传输率之比:
永远记住
其中 为码元符号的种类数(如二进制编码 )。

3.4 码冗余度 ()
4. 信源扩展编码
当单一符号编码效率不高时,可以采用 次扩展信源编码(对符号组进行编码)。
-
结论:信源扩展后,平均每个信源符号的信息量不变。
其中 是平均每个原始信源符号的等效码长。
香农第一定理 (无失真信源编码定理)
只要码长 足够长,总能找到一种编码方式,使得平均码长满足:
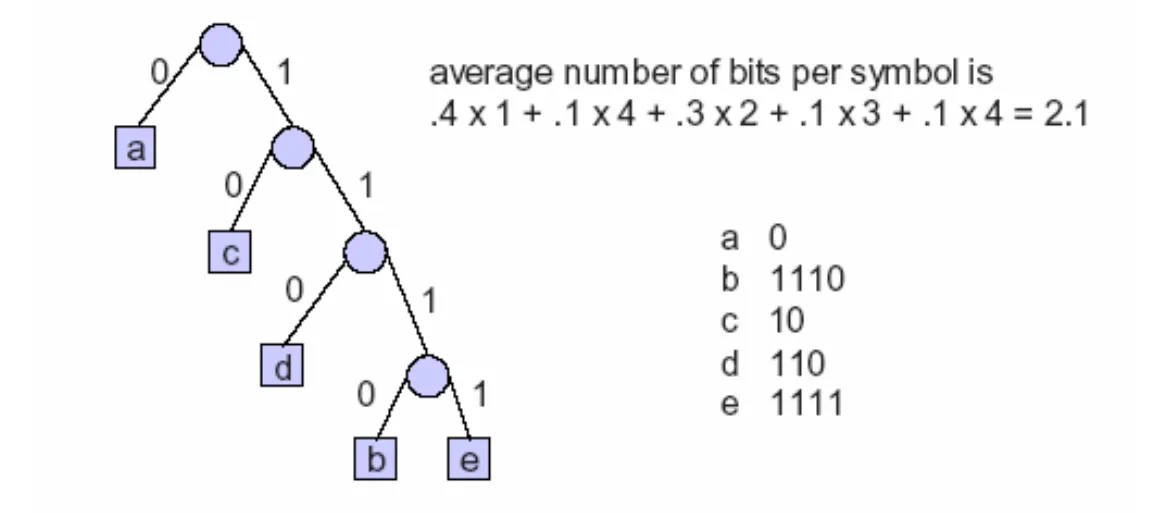
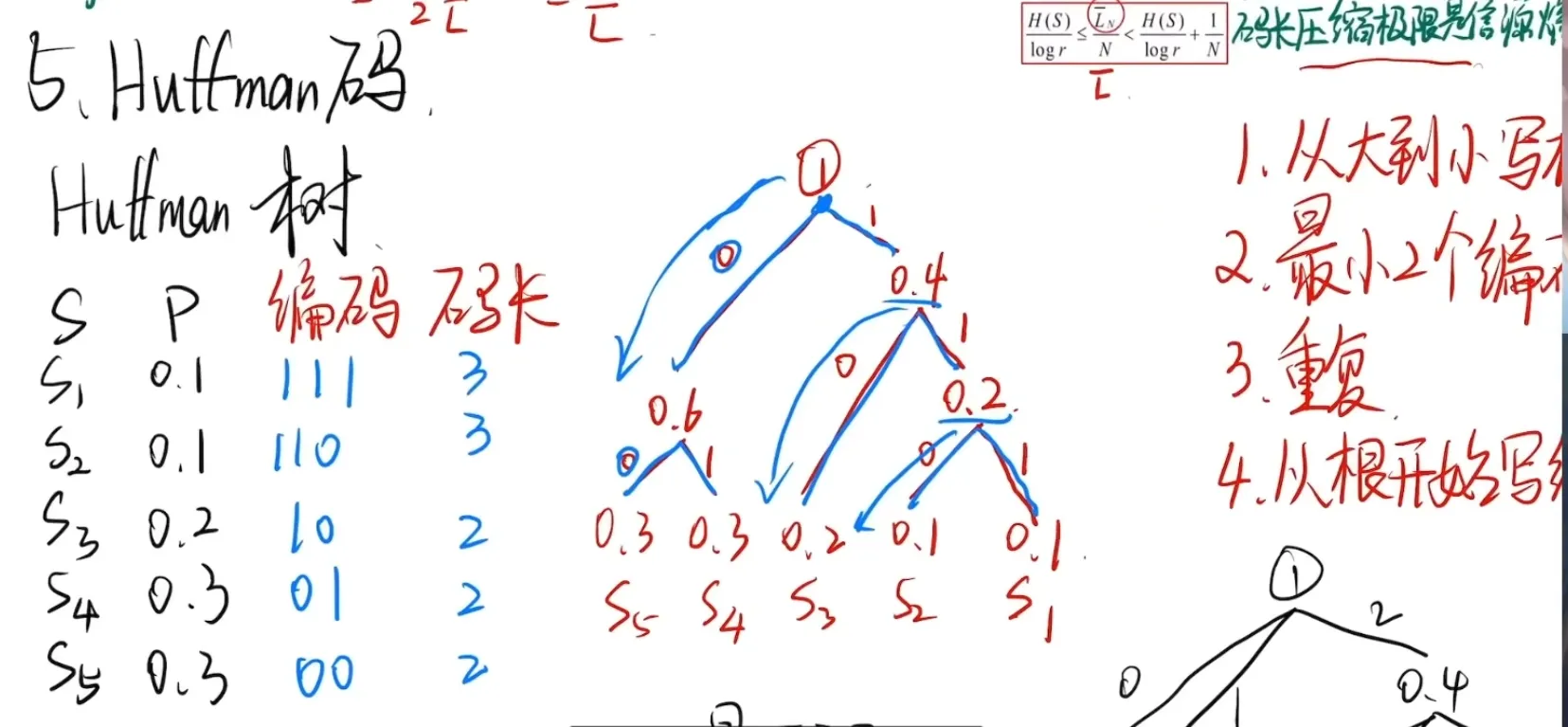
5. 紧致码:Huffman 编码 (Huffman Coding)
Huffman 编码是一种能使平均码长最小的变长编码算法。
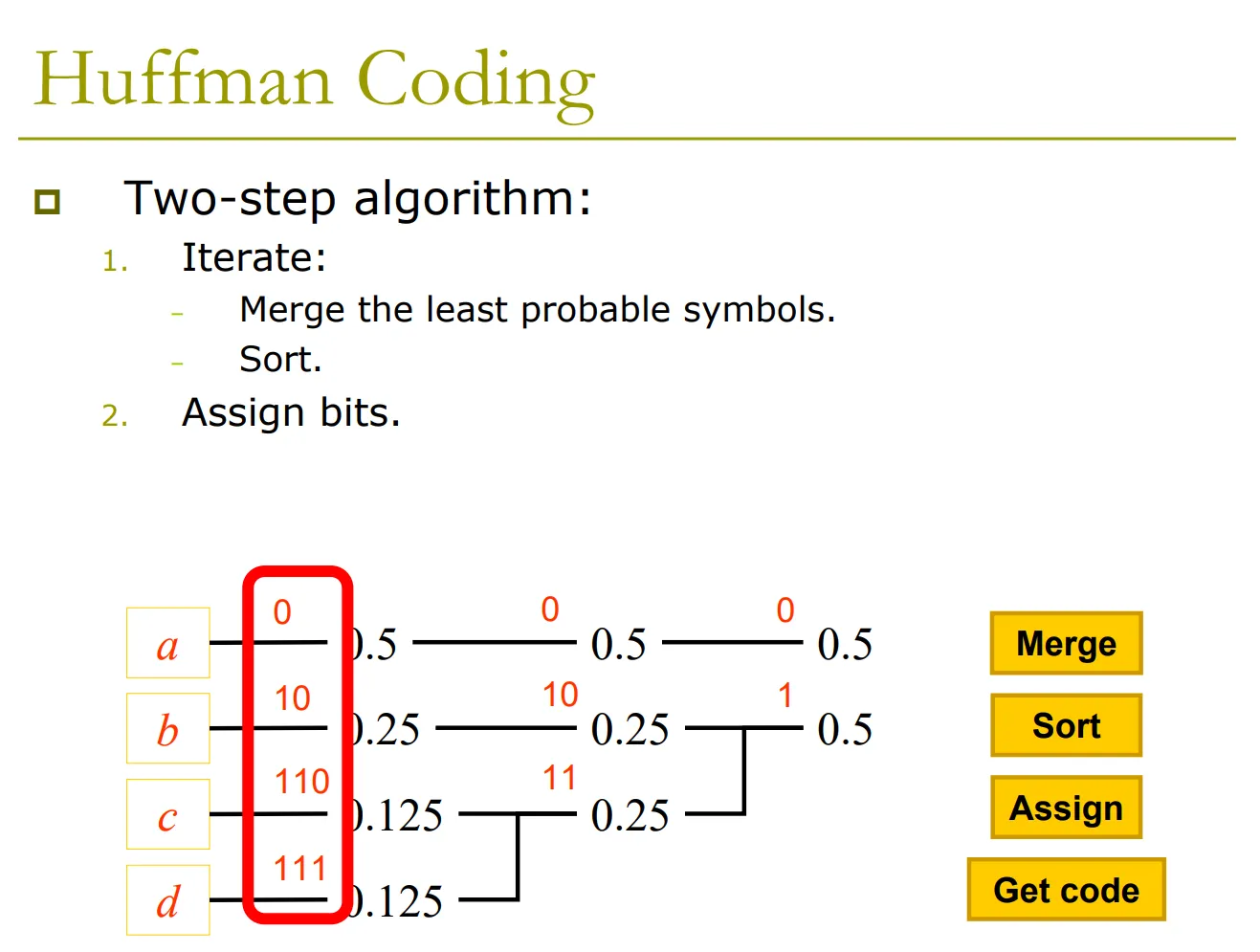
5.1 二进制 Huffman 编码步骤
- 排序:将信源符号按概率从大到小排列。
- 合并:将概率最小的两个符号合并为一个新节点,概率为两者之和。
- 重复:对新序列重新排序,重复合并,直到最后只剩一个概率为 1 的根节点。
- 赋码:从根节点出发,每个分支分别赋 0 或 1,记录下各路径即为码字。
5.2 进制 Huffman 编码
- 每次合并概率最小的 个节点。
- 注意:若符号数 不满足 ,需要添加概率为 0 的“虚符号”补齐。
6. 限失真信源编码 (Rate-Distortion Theory)
这里我没有仔细看,如果真的要考,那么优先看上面的这个视频。
在允许一定失真的情况下,进一步压缩数据。
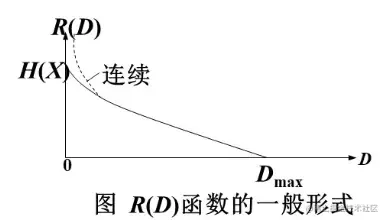
6.1 失真矩阵 (Rate-Distortion Theory)
表示输入 却输出 时的失真程度。
函数是在允许一定失真条件下,平均互信息的最小值。
6.2 最小失真 与最大失真
-
计算 : 每一行挑选最小的失真值(通常为 0),再与 加权求和:
-
计算 : 假设输出与输入完全无关(选择一个最佳的固定输出 ),计算各列的加权和,挑出其中的最小值:
如何求满足保真度 的实验信道
在错误概率最小处填1,其他填0
香农第三定理 (限失真信源编码定理)
只要码长足够长,一定能找到一种编码,其失真度非常接近给定的失真限制要求。
7. 典型例题解析
例题:二元信源

- 直接编码:效率极低,。
- 二次扩展编码:
- 信源符号变为:。
- 进行 Huffman 编码后,计算 ,得出 。
- 效率 显著提升。
例题:四元对称信源

- 概率分布:。
- 失真矩阵 :主对角线为 0,其余为 1。
- 计算结果:, 。